StreamX Processing Service
StreamX Processing Service is a category of a microservice that facilitates the processing of data pipelines. You can use them for building blocks in the processing layer of the StreamX Mesh. StreamX Processing Service Extension uses Quasar framework, which enables stateful computation, messages synchronization between channels and service instances, and ensures no outdated message are processed. It plays a key role in executing business logic and transforming data, situated in the middle of StreamX Mesh, between inboxes and outboxes channels.
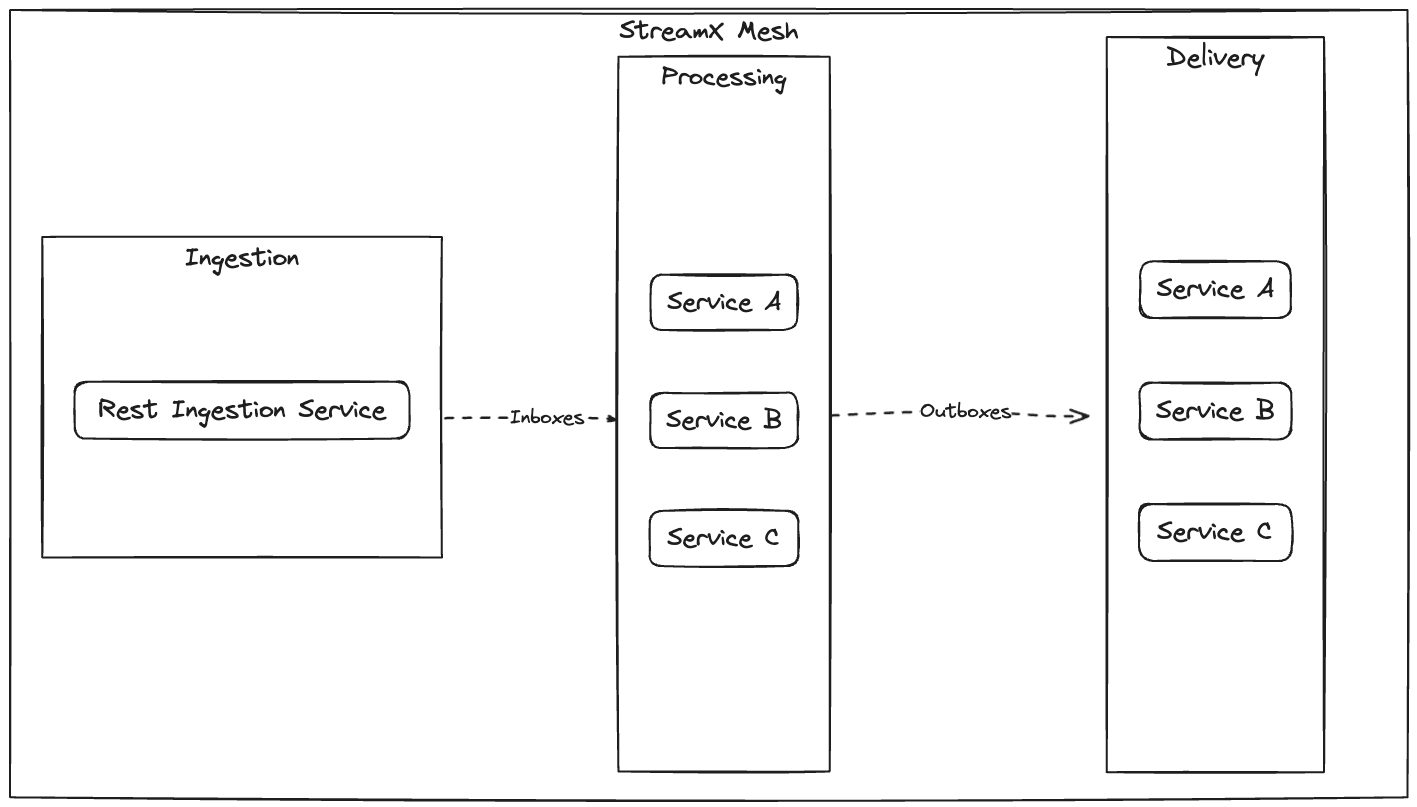
StreamX Processing Service Extension
StreamX Processing Service requires the StreamX Processing Service Extension dependency. The StreamX Processing Service Extension is a Quarkus Extension that includes the Quasar Extension. StreamX is designed to work with different messaging systems by using SmallRye Reactive Messaging. The default implementation is based on the Apache Pulsar messaging system.
Maven dependency
To use Maven, add the following dependency to your pom.xml and define the version in the version property.
<dependency>
<groupId>dev.streamx</groupId>
<artifactId>streamx-processing-service</artifactId>
<version>${version}</version>
</dependency>Adding Streamx Processing Service Extension supplies the project with the following Quasar capabilities and default configurations for channels.
Quasar capabilities
-
Stateful storage
-
Messages synchronization
-
Outdated messages rejection
-
Metadata enrichment
Supported Metadata
StreamX enables functions to use Quasar Metadata. By default, strict mode is enabled, which means that messages without Quasar metadata are skipped. This ensures safe usage of the metadata. You can change this behavior by disabling the strict mode:
quasar.messaging.metadata.strict=false
|
When strict mode is disabled, Quasar metadata might not be present, and you must validate it yourself |
You can choose from the following types:
-
Key - Identifier of a data item
-
Key can contain optional namespace prefix. If key contains at least one
:character, then fragment before first:character is namespace.
-
-
Action - Publication action (publish/unpublish)
-
EventTime - Time of data publication into StreamX Mesh
Default configuration
Service ID - identifier of the service - should be common for all replicas of the service.
streamx.service.id=${quarkus.application.name}
Default configuration for StreamX Processing Service consumer
StreamX Extension provides default streamx-processing-service-consumer-default-config. This default config might be applied to channel by adding line:
mp.messaging.incoming.[channel-name].consumer-configuration=streamx-processing-service-consumer-default-config
Then such configuration:
mp.messaging.incoming.[channel-name].subscriptionInitialPosition=Earliest
mp.messaging.incoming.[channel-name].subscriptionType=Shared
mp.messaging.incoming.[channel-name].subscriptionMode=Durable
mp.messaging.incoming.[channel-name].subscriptionName=${streamx.service.id}
mp.messaging.incoming.[channel-name].deadLetterPolicy.initialSubscriptionName=${streamx.service.id}
mp.messaging.incoming.[channel-name].deadLetterPolicy.maxRedeliverCount=3
mp.messaging.incoming.[channel-name].poolMessages=true
mp.messaging.incoming.[channel-name].ackTimeoutMillis=60000
is applied to given channel.
Default configuration for StreamX Processing Service producer
StreamX Extension provides also default streamx-processing-service-producer-default-config. This default config might be applied to channel by adding line:
mp.messaging.outgoing.[channel-name].producer-configuration=streamx-processing-service-producer-default-config
Then such configuration:
mp.messaging.outgoing.[channel-name].producerName=${streamx.service.id}
mp.messaging.outgoing.[channel-name].accessMode=Shared
is applied to given channel.
StreamX Extension scans your service and if there are only processing methods, it is considered a processing service, and default configurations are applied without any user interaction. For more advanced
setup you can disable this behavior by setting streamx.channels.default-config.enabled to false. In that case you should provide all required configurations on your own.
|
Processing Function
In most cases, Processing Function is a Java method annotated with both @Incoming and @Outgoing annotations.
However, there might be some special cases where you might need just @Incoming or @Outgoing which is also supported.
StreamX uses SmallRye Reactive Messaging, so you can use any
data processing method signature
offered by SmallRye.
The recommended signature uses GenericPayload.
@Incoming(INCOMING_CHANNEL)
@Outgoing(OUTGOING_CHANNEL)
public GenericPayload<Page> relay(Page page) { ... }You can pass any supported metadata to method arguments. They are optional, so you can choose only the ones you need.
@Incoming(INCOMING_CHANNEL)
@Outgoing(OUTGOING_CHANNEL)
public GenericPayload<Page> relay(Page page, Key key, Action action, EventTime eventTime) { ... }In cases where you want to create multiple outputs from a single input, you must work with Messages.
@Incoming(INCOMING_CHANNEL)
@Outgoing(OUTGOING_CHANNEL)
public Multi<Message<Page>> relay(Message<Page> message) { ... }Some functions in processing services might only consume messages and outgoing messages might be sent out by using Emitter.
In such cases, you can use only @Incoming annotation and Emitter
@Incoming(INCOMING_CHANNEL)
public void consume(Payload payload) { ... }@Inject
@Channel(OUTGOING_CHANNEL)
Emitter<OutputPayload> emitter;
public void send(OutputPayload out) {
emitter.send(out);
}Messaging channels
Processing functions typically consume messages from external sources and send them out through an outgoing channel. In such scenarios, StreamX uses a messaging system under the hood. By default, StreamX uses Apache Pulsar. In cases such as testing, where you do not need a messaging system, you can use an in-memory channel.
Channel configuration
To switch between the available options, you must set up a connector for each incoming and outgoing channel:
mp.messaging.incoming.[incoming-channel-name].connector=smallrye-in-memory mp.messaging.outgoing.[outgoing-channel-name].connector=smallrye-in-memory
In most cases, you want your data processed by different processing functions (different microservices), so you need a messaging system to communicate with them. StreamX provides a set of default configurations that you should use for both incoming and outgoing channels:
mp.messaging.incoming.[incoming-channel-name].connector=smallrye-pulsar mp.messaging.incoming.[incoming-channel-name].consumer-configuration=streamx-processing-service-consumer-default-config mp.messaging.incoming.[incoming-channel-name].topic=inPagesTopicName
mp.messaging.outgoing.[outgoing-channel-name].connector=smallrye-pulsar mp.messaging.outgoing.[outgoing-channel-name].producer-configuration=streamx-processing-service-producer-default-config mp.messaging.outgoing.[outgoing-channel-name].topic=outPagesTopicName
streamx-processing-service-consumer-default-config and streamx-processing-service-producer-default-config identify provided configurations for Pulsar consumer and producer.
You can still override any property for a given channel:
mp.messaging.outgoing.[channel-name].propertyName=propertyValue
Channel schema
StreamX works with Avro schema.
To register a schema for use in a channel, you must create a data model annotated with @AvroGenerated and include it in signature of a method annotated with @Incoming.
The model class must contain a public, no-argument constructor, which is required for the serialization process.
@AvroGenerated
public class Data {
public Data() {
// needed for Avro serialization
}
// ...
}You can also use objects that are not annotated with @AvroGenerated, but you must provide a
Message Converter in such cases and explicitly configure the channel schema.
import org.apache.pulsar.client.api.Schema;
// ...
@Produces
@Identifier("channel-name")
Schema<Data> dataSchema = Schema.AVRO(Data.class);When any service registers a new schema for inboxes channels, it is automatically available for the REST Ingestion Service.
Blocking processing
Processing function should be fast because they are executed on the event loop thread.
However you might have to run some long running code like heavy processing or blocking IO operations.
In this case, annotate your method with the @Blocking annotation, which moves the processing to the worker thread.
To read more about reactive architecture on Quarkus guide.
Store
Store can keep the state of the data from the incoming channel. A processing function can use zero, one, or many stores. Stores enable functions to process incoming data based on the state of incoming channels. Quasar ensures that data in the Store is fresh and all service instances share the same view of the data. Stores backed by Pulsar topics have schemas generated automatically from generic types. Like processing methods, Stores also support message converters.
Store declaration and usage
Annotate Store<Data> with @FromChannel("incoming-data") to access the state of the incoming-data channel.
@ApplicationScoped
public class FunctionBean {
@FromChannel("incoming-data")
Store<Data> dataStore;
@Incoming("incoming-data")
@Outgoing("outgoing-data")
public GenericPayload<Data> process(Data data, Key key) {
Data fromStore = dataStore.get("some key");
// processing data with fromStore data
return GenericPayload.of(processedData, newKey);
}
}|
Store keeps the most recent data. You should never call it twice while processing a single message, because the data could change in the meantime. Instead, create a variable to hold the data from the store. |
Store synchronization
Stores keep data in sync between service instances and between Store instances. This means a function can start processing a message once all stores are in sync (for example, have all data present until the message arrived). You can choose from two available synchronization modes:
-
ALL- Every store in the application is up to date. Default mode. -
CHANNELS- Every store created from the same channel is up to date.
Use quasar.messaging.store.synchronization.mode=CHANNELS to change the sync mode.
Use connector
Stores do not always have to be backed by a messaging system. When you do not need data synchronization and persistence, you can exclude it by configuring:
quasar.messaging.store.[store-identifier].use-connector=false
[store-identifier] consists of [channel]_[store class simple name]-[store type class simple name].
Multiple instances
StreamX is designed to be scalable.
You can use any number of processing function (service instances) required.
The Quasar framework ensures that data in Stores are in sync between instances.
The load is distributed among all instances using Shared subscriptions for incoming channels.
Message acknowledgment
When you work with GenericPayload or payloads, framework acknowledges the messages for you without any interaction.
By default, messages are acked after processing is finished and nacked when exception is thrown from the function.
However, when you use the Message<> object, you have to ack or nack the messages manually.
If message is not acked in given timeout, it is redelivered and processed again.
See SmallRye Message Acknowledgment for more details.
Failure handling
There are several cases where things can go wrong. Few examples:
function throws exception, message can not be processed and is nacked manually or message could not be delivered within timeout.
Message is redelivered configurable number of times and if it reaches the limit, it is sent to dead letter topic.
You can use this topic to take some action on failed messages.
The Dead-letter-topic is created in the same namespace where incoming channel’s topic resides.
The name of Dead-letter-topic is [channel’s topic name]-DLQ.
You can change this behavior by setting a different failure strategy.