Digital Experience Mesh overview
The Digital Experience Mesh is a modern web architecture paradigm created to address the challenges of web data orchestration, distribution, and delivery. It offers an alternative to solutions built around monolithic applications that use the request-reply model and are heavily dependent on caching. By employing the Digital Experience Mesh, architects can create clean, composable solutions that are both scalable and high-performing.
The Digital Experience Mesh is distributed, event-driven, and eventually consistent. It relies on multiple single-purpose, specialized processing services and a high-performance messaging system. It processes and pushes data from source systems to delivery services deployed close to end users. This approach eliminates runtime dependencies on source systems, ensuring predictable low latencies for both static and dynamic resources, even under heavy load and across various geographic locations.
| This document covers the Digital Experience Mesh, the concept behind StreamX. It provides the reasoning, requirements for the new system, key assumptions, decisions, and the problems solved by the architecture. Its purpose is not to describe the implementation or configuration details of StreamX. |
This document will guide you through the architecture, explaining why the Digital Experience Mesh was created, the problems it solves, its core features and capabilities, and the decisions behind its design.
Why this architecture is needed
Most web systems, such as e-commerce platforms, CMS, PIM systems, or custom applications, are monolithic applications with multi-layer architectures. This well-known, easy-to-implement, and maintain architecture style becomes equally difficult to scale and manage in more complex environments, especially when multiple systems must co-exist. We’ve been facing multiple innovative trends, such as Single-Page Applications (SPA), Progressive Web Applications (PWA), and micro-frontends. These trends were gaining popularity with modern frameworks like React, Angular, and Vue on the frontend. There are emerging backend technologies like service meshes, serverless computing, data streaming, and containerization. However, there is a lack of comprehensive web architectures that allow engineers to build modern solutions without having to design the architecture from scratch.
Evolution of the web systems
To understand the limitations and challenges, it’s important to define the most common web system architectures. These architectures include monolithic systems, distributed monolithic systems (a cluster of monoliths), and distributed MACH architecture. Each architecture will be described by using example diagrams of CMS deployments.
| The architectures shown in this section are just examples and can vary depending on the specific product or implementation. Moreover, in most organizations, the web system is composed of multiple other systems, integrated together to create a single site, mobile application, or web application. |

The first and probably most common web system architecture is a single monolithic application shared by two types of users: contributors (for example content authors) and visitors. This is how most CMS systems are built; if you think about a monolithic application, this is likely the model example. It’s simple to set up, monitor, and maintain because it uses a single database and a single application running on one server. All the features are developed within a single codebase, so functions like authorization, authentication, digital asset management, full-text search, tagging, and publishing are already available. If integration is needed, it is done within the same codebase. However, the simplicity and completeness of this architecture become problematic because system complexity grows or when it must scale to handle a large number of publications or high traffic.
-
The same instance is shared between two types of users: content authors and site visitors, each requiring different system characteristics. Authors need a platform to manage content and the publication process in a transactional manner. The application is often accessed from a single location. Visitors, on the other hand, need a fast and highly available system that works reliably across various geographic locations.
-
Monolithic applications are hard and expensive to scale. In most cases, vertical scalability is supported, where operators can assign more resources to a server. This approach is limited by the physical capacity of the hardware, hence can easily reach its limits.
-
Running the application on a single physical machine, often in a single process, forces all functionalities to share the same resources, such as memory, CPU, network, and disk. This can lead to situations where one functionality negatively impacts others. For example, a traffic spike can cause an outage for content authors, and an inefficient search query can cause the website to become unavailable.
-
The system includes many features, but it’s often not designed for extensibility. Extending such a platform to use a different search engine or user management system can be expensive and time-consuming.
-
The system is designed to work on a single physical server, making it difficult to deploy to multiple locations. Data replication and maintaining consistency across replicas becomes a challenging task.
-
There are security issues because the instance responsible for creating/managing content and communication with internal systems is exposed to public traffic.
-
The frontend is tightly coupled with the backend, and rendering is often mixed with business logic.
| While this section focuses on a traditional CMS example, these challenges are also common in other monolithic applications. |

Over the past two decades, vendors have tried to address these issues with monolithic applications. The diagram above shows a common architecture used by an enterprise CMS (often called Web Content Management (WCM) or Digital Experience Platforms (DXP)). The key changes to the original CMS architecture are:
-
Decoupling authoring instances from rendering instances.
-
Introducing an additional caching layer that can be controlled by publication workflows.
-
Moving the authoring instance to the DMZ, limiting connectivity between renderers and the authoring instance.
-
Introducing data replication mechanisms to distribute content from the authoring instance to rendering instances.
This architecture addressed some of the issues and was a step in the right direction. Enterprise CMS systems can handle more load due to the use of multiple rendering instances and are more secure because public traffic cannot directly access backend instances. However, many problems are inherited from traditional monolithic architectures, and additional operational and maintenance challenges make this option suitable only for enterprise customers.

A relatively new alternative to the monolithic web system is the MACH architecture. It limits the role of systems like CMS, PIM, or e-commerce to that of data providers. In most cases, frontend technologies are responsible for rendering and logic is moved to the microservices layer. All is controlled in a cloud-native environments.
| MACH architecture is a collection of loosely coupled principles, unlike monolithic systems like CMS systems, which follow well-defined architectures. MACH systems, such as headless services, are components rather than complete solutions. They lack standardized frameworks, making each implementation unique and essentially a custom project. |
By definition, MACH architecture solves the following issues:
-
Composability: MACH allows you to build a composable solution from the services the team needs. It often enables the choice of best-of-breed services, such as search or recommendation engines.
-
Scalability: Unlike monolithic applications, MACH relies on microservices, meaning most system components can be scaled independently. This helps handle additional load when needed and introduces savings by scaling down services when resources are not fully used.
-
Maintainability: By utilizing cloud technologies, MACH can improve maintainability, decrease operational costs and improve efficiency.
-
Offloaded CMS responsibilities: In this setup, the role of the CMS (or any other data-providing system) is primarily reduced to that of a content source, typically without providing additional services.
With its benefits, MACH can introduce additional challenges:
-
The system based on this architecture is more expensive to implement, because it requires careful design, especially when multiple systems are involved.
-
There is a lack of blueprints and standards around MACH architecture; therefore, implementation involves making numerous decisions, which increases risks and time to implement solutions.
-
While it’s simple to get started with a single headless backend and a single frontend, MACH might become difficult to manage when multiple systems must communicate or if the web system is complex (with extensive logic, multiple channels, and many service variants).
-
If not implemented correctly, MACH can become tightly coupled and hard to maintain.
-
Observability might be challenging in distributed environments that connect multiple systems, and uses many microservices.
-
It is challenging to orchestrate data and systems. In most cases, this is done on the frontend side, which can increase complexity and affect system performance or require a custom backend module like an ESB.
-
Instead of depending on one content source and one system, MACH architecture relies on multiple backends. This might introduce new challenges, because each backend must be scaled and maintained individually without affecting the overall system.
| The Digital Experience Mesh is designed to be MACH-compliant. It does not require all systems to be headless or deployed in the cloud, but it fully supports these features. It is designed to overcome traditional web system limitations and to be a blueprint for creating robust MACH solutions. |
Challenges of the web systems
There is a group of challenges common to most web systems. Not all of these issues occur simultaneously, but they are recurring problems. Modern architecture should address all of them.
-
Scalability:
-
Delivery: As web traffic grows, systems must be able to scale the delivery layer to handle increased load.
-
Processing: The system must be able to scale its processing and data layers to process data from source systems (like publications).
-
-
Performance:
-
Delivery latency: The system must ensure low response times and network latencies in various geographic locations.
-
Processing latency: Data must be processed with the lowest possible latency, ensuring that the data presented to the visitor is relevant.
-
Rendering latency: The system should ensure that the web resources are optimized and can be rendered quickly on a visitor’s device.
-
-
Reliability and Availability: The system must be highly available and provide responses with consistent performance, independent of the backend systems' locations, availability, and performance.
-
Data Consistency:
-
Delivery data: Data presented to visitors must be up-to-date. It cannot come from stale caches or from a system in an under-replicated state.
-
Processing data: All services must operate on the same set of data and present consistent results regardless of location or instance.
-
-
Cost Efficiency: The system must be able to scale only the components that require additional resources or instances to avoid introducing unnecessary costs.
-
Security: The system must be secure by limiting access to backend systems or data that should not be exposed on the public internet.
-
Complexity of Integration: Integrating multiple systems, APIs, and services into a cohesive web system should be based on contracts. Introducing new systems should not require point-to-point integrations, which are hard to maintain and costly.
-
Geo-replication of Data and Services: The system should be able to operate in multiple geographic locations, even with temporary network failures between components.
-
Cache Management: System availability should not depend on cache, especially HTTP caching servers or a CDN.
-
Legacy Systems: The system’s availability and performance should not depend on the availability and performance of legacy systems.
-
Data Orchestration: The system should provide the capability to orchestrate data coming from multiple source systems.
-
Data Processing: The system must be able to process large volumes of data from source or external systems. Data changes must be reflected in the final states of services, for example, through updates to web resources. These changes should be available to visitors in near real-time.
One of the main challenges is that web systems do not operate in isolation. They rely on data and services from other systems, all evolving at different rates, with protocols and formats changing over time. These systems and services have varying performance and scaling characteristics, they might be deployed in different geographic locations and accessed through different networks. Each one can have distinct security policies, yet they must work together to produce a consistent, reliable, and high-performing web system.
The need for the next-gen architecture
To address the challenges unresolved by current solutions, we must start exploring alternative approaches. Instead of building yet another architecture around headless systems with a serverless computing layer and modern frontend frameworks, we should first ask: what’s wrong with the current approaches? The key observation is that we must decouple source systems from the processing and delivery layers. Each of these layers has different responsibilities and characteristics.
| Layer | Characteristics |
|---|---|
Sources |
Layer containing multiple source systems, each might be deployed to a single geographic location. Must allow contributors to make changes to data in a consistent way. Can tolerate minor system unavailability, and performance is not critical. |
Processing |
Data processing and distribution is responsible for orchestrating data from multiple sources, performing processing, and distributing it to edge locations. It must be able to store and replay its state when needed. Processing must be horizontally scalable but can be deployed to a single region to reduce end-to-end processing latencies. This layer must be fault-tolerant, and the risk of its unavailability must be minimized. |
Delivery |
This layer is responsible for delivering content to visitors. Like a CDN, it must respond with minimal latency and be efficient. It must be deployed close to the end users and serve pre-processed data. However, unlike a CDN, it should also support services like searches or custom APIs. This layer must be replicated, with local copies of data for each geographic location. It must be able to scale horizontally, with full redundancy to prevent potential unavailability. |

With an understanding of these three layers, it’s time to move on to the communication between them. It stands to reason that the highly available, distributed delivery layer must not make direct requests to source systems, which might be legacy, relatively slow, and not scalable. Furthermore, given the challenges engineers face with various caching mechanisms, the system should not be overly dependent on the caching layer. This could lead to a system that is unstable when the cache is flushed, or outdated when the cache contains stale data. To build a system that contains up-to-date data and does not depend on cache or backend systems' availability and performance, we must change the communication model. In that model the Digital Experience Mesh must be informed of any relevant changes occurring in source systems. These changes, such as page publications, product description updates, or user profile changes, must be sent in the form of events. It then executes a set of actions to reflect the state of the backend systems in the delivery services. With this model, the architecture always generates resources and updates the service state before a visitor makes a request.
Moreover, since we are defining a composable architecture, it naturally must be message-oriented.
| Along with dividing the system into three layers-sources, processing, and delivery-there is an additional principle worth to know from the start: "Pre-generate everything possible before it’s requested, but nothing more." |
Not all resources can be pre-generated and used unchanged by the delivery service. A good example is search - we can’t generate a response to a search query if we don’t know what the request will be. In such cases, the system should provide a search service at the delivery layer that uses pre-processed data to create local state and generate a response by using an optimized index. This allows the delivery services to respond fast and scale efficiently.
At this point it’s important to emphasize that the Digital Experience Mesh is:
-
Distributed
-
Event-driven
-
Stateful
These three principles enable us to decouple site performance and availability from source systems. They allow us to process large amounts of data in real time and deliver both static and dynamic resources globally through a high-performance, scalable system. Further details will be covered in the following sections.
Key architecture characteristics
The main issue with scaling solutions around traditional web systems is that they are designed to be multipurpose applications. The same application must meet different, often conflicting requirements. Traditionally, a CMS must be both transactional and highly consistent to enable collaboration between authors, while also being eventually consistent and distributed (especially in enterprise deployments) for handling web traffic. Traditional e-commerce systems are built to manage inventory, stock, prices, categories, and promotions for back-office users. Their second role is to be a storefront that must be high-performing, scalable, and highly available for visitors.
Decoupling source systems and making them data providers only, each with its own characteristics, is a key decision in building an effective web system architecture. Before defining the components, communication methods, guarantees, or technological choices for the Digital Experience Mesh, it is essential to first establish the characteristics that the architecture must provide.
| Many important characteristics are not mentioned in this section; the focus is only on those related to common problems in web systems. |
|
This section defines core architecture capabilities. |
Performance, scalability and availability
The first group of characteristics relates to web system performance, scalability, and availability. These characteristics vary across different layers. For example, performance can be measured by using different metrics for a DAM source system, an image processing service, and the web servers hosting the images.

For a DAM system, performance is measured by how fast an image can be uploaded and stored in the database. In the processing layer, performance is evaluated by the end-to-end latency of handling conversion requests and distributing the converted images to web servers. For web servers, performance is measured by the latency in accessing publicly available files. Scalability follows a similar pattern. For a DAM system, it refers to the number of images that can be stored and managed. In the processing layer, it refers to the throughput, which includes the number of conversions and the amount of data transmitted. For web servers, scalability is measured by the number of visitors that can access the assets simultaneously.
| We cannot assume any characteristics of the source systems, because these are pre-existing systems in enterprise setups. Most organizations already have multiple data sources, such as DAM, CMS, e-commerce platforms, or legacy APIs. What we can define is that the processing and delivery layers must be decoupled from the source systems. |
|
Source systems performance, availability and scalability should not affect processing and delivery characteristics. |
The following are the first required characteristics for the system:
-
Performance for processing: The system must ensure low end-to-end latencies in handling tasks such as data orchestration or content processing. This should be measured by the time taken to process events and distribute results to the delivery layer.
-
Performance for delivery: The system must respond to user requests quickly and reliably. Latency must remain consistently low for every request, even under heavy load or when caches are not fully populated.
-
Scalability for processing: The system must be able to scale to handle additional data sources, increasing data volumes, or more destinations. This might require scaling the processing services or the communication layer between them. The system must be capable of horizontal scaling.
-
Scalability for delivery: The system must be scalable to handle increasing traffic, including serving more users or delivering more content. It must be capable of horizontal scaling, either within a region or by adding additional regions.
-
Availability for processing: The processing layer must remain operational and highly available, even in case of failures. This requires redundancy and fault tolerance to ensure continuous operation during network issues, data center outages, service failures, or data corruption. Data and services must be replicated with at least a replication factor of two, balancing cost and availability to minimize downtime and service disruption.
-
Availability for delivery: The delivery layer must maintain high availability, ensuring that content remains accessible to users, even during traffic spikes or system failures. Each geographic region where delivery services are deployed must operate independently, with its own local copy of data and necessary services. The level of redundancy for both data and services must correspond to the number of regions, and additional redundancy should be implemented within each region to further improve fault tolerance.
| Geo-replication plays an important role in the Digital Experience Mesh architecture. It reduces network latency between client devices and the delivery layer, ensures that services operate on local copies of data, and improves availability by leveraging redundancy in both data and services. |
Reactive System principles
Another group of characteristics is derived from the Reactive Systems architectural principles. Although the Digital Experience Mesh implementation does not explicitly require being a Reactive System, applying its principles might be the best approach for achieving a well-designed system architecture.
Reactive Systems are:
-
Responsive: The system responds in a timely manner if at all possible.
-
Resilient: The system stays responsive in the case of failure.
-
Elastic: The system stays responsive under varying workload.
-
Message-Driven: Reactive Systems rely on asynchronous message-passing to establish a boundary between components that ensures loose coupling, isolation and location transparency.
The principles of reactive systems are important at the application level. They can be implemented through modern reactive programming libraries, non-blocking I/O, patterns like the event loop, and asynchronous processing. Additionally, these principles help define contracts between components. Asynchronous, message-driven communication ensures loose coupling between different parts of the system, improving both scalability and resilience, while also contributing to a clean and transparent architecture.
| Learn more about Reactive Systems by reading the Manifesto |
Other characteristics
The final group of characteristics is not directly related to scalability, performance, or availability, nor are they derived from the principles of Reactive Systems. However, these issues have been recognized challenges in traditional monolithic web systems and remain unresolved - or have even worsened - in modern architectures like MACH.
To address these challenges, systems must provide a high level of:
-
Integrability: The ability of a web system to seamlessly connect, exchange data, and operate in conjunction with other systems, applications, and services, both internally and externally. Integrating multiple solutions into a monolithic web system is often challenging. However, modern approaches often shift integration to an API Gateway or directly to the user’s browser, which increases complexity on the frontend side and can degrade performance. A modern web system should be a middleware enabling and governing the flow of data between services, applications, and platforms.
-
Composability (Modularity): The ability to break down a web system into smaller, independent components or modules, each responsible for specific functionality. This modular approach allows for building larger systems from best-of-breed components or replacing parts of the system without affecting other modules. Monolithic systems often suffer from tightly coupled components, making changes difficult to implement. Modern systems embrace microservices and modularity, but this can lead to increased operational complexity, with many services requiring orchestration. A modern web system should enable components to communicate by using standard protocols and provide an environment for deploying, monitoring, and exchanging data between them.
-
Security: The protection of a web system from threats ensures data privacy, integrity, and availability. In traditional systems, security vulnerabilities are more pronounced because a single instance often exposes numerous functionalities. Potential breaches are more dangerous, because attackers can gain access to a broader range of the system. This issue is mitigated in modern architectures, such as microservices, but the large number of services with different characteristics requires comprehensive global security policies. A system should provide a framework with clear boundaries between publicly available services and those that are not. It must also ensure that communication between services is secure and consistent, without increasing the attack surface.
-
Traceability: The ability to track and monitor system activities, including user actions and internal processes, to ensure that the application is functioning correctly and to quickly identify potential problems or bottlenecks. This characteristic is especially important in distributed systems, because in monolithic systems, we could often rely on logs, stack traces, memory dumps, or operating system tools. A modern web system must provide comprehensive tools for monitoring all its components, including tools for collecting and analyzing logs, traces, and metrics. Additionally, effective alerting mechanisms are essential for timely issue detection.
Key guarantees
Defining the guarantees a system must fulfill is crucial in shaping its architecture. Since the Digital Experience Mesh is designed specifically for web-related use cases, certain design decisions can be made with a focus on web-specific needs. This cannot be achieved by a general-purpose framework or architecture.
Consistency model
The web is eventually consistent by default, and so is the Digital Experience Mesh. Enforcing strong consistency would make it practically impossible to meet the requirements for high performance, scalability, and availability. In distributed web systems components might be responsible for various functionalities. In that case, it is safe to accept that, for example, a page will be available on a web server shortly before it’s available in the search index. We can also accept situations where changes to a content resource are visible in one geographic location slightly faster than in another.

It might seem obvious that a distributed system is eventually consistent. However, making it a clear requirement allows us to design the system’s components keeping this in mind. If the entire system is eventually consistent, the subsystems are not required to provide strong consistency.
| The processing layer is responsible for processing and distributing data to the delivery services. It is designed to handle high volumes of data with low millisecond latencies. In practice, it might provide a system state consistency that is closest to that of a monolithic application with a transactional database. |
| Eventual consistency is the default consistency model used by the Digital Experience Mesh. However, it is still possible to provide strong consistency at the service level, such as for processing transactions or ensuring stock availability. |
State synchronization
Digital Experience Mesh scales horizontally, meaning that it’s possible to have more instances of a single service. The system must guarantee that before enabling a new instance of a service, its state must be consistent with other instances. This is a guarantee that must be met for both processing and delivery services.
-
Processing layer: State synchronization must be ensured before processing incoming requests to prevent services from working on outdated data. For example, consider two rendering engines responsible for generating pages based on templates and JSON payloads. If these engines are not properly synchronized, and one instance receives updated templates while the other does not, they will process the same requests differently. One engine might render pages with the old template, while the other uses the new one, causing a visible inconsistency across the user experience. This example highlights why the processing layer must ensure state synchronization—without it, outdated or conflicting data can lead to unpredictable and undesirable outcomes.
-
Delivery layer: State synchronization must be performed on startup to prevent delivery service instances from serving mismatched versions or quantities of resources. For example, when a new web server is added to the pool, if the instance isn’t synchronized before going live, it might temporarily return 404 HTTP error codes. This scenario underscores the necessity of ensuring synchronization at startup to avoid disruptions in service delivery.
Multi-location availability
The Digital Experience Mesh must be able to operate in multiple geographic locations. This is especially important for the delivery layer, which can potentially use edge locations to minimize network latencies for requests coming from users. New regions can be added without reconfiguring the rest of the mesh components, and old regions can be decommissioned at any time.
| See: Location transparency in the context of Reactive Systems. |
Messages delivery
Messages sent to the Digital Experience Mesh are guaranteed to be processed at least once. In rare cases, the same message might be delivered more than once, such as when a processing service times out while handling the request, prompting the system to re-deliver the message. As a result, duplicates are possible in exceptional scenarios. This could lead to situations where the web server is instructed to save the same page twice or the search engine is asked to index the document again.
Messages delivery order
Messages are processed and delivered in order for each key. Therefore, a key must be assigned to each message sent to the system. This key could be a resource path or a product SKU number.
The system must guarantee that messages with the same key are delivered in the order they were sent. However, due to processing failures or network latencies, a newer version of a message with a given key might sometimes be delivered to a service before the previous one. In such cases, the service can ignore the outdated message.
| The system must provide a mechanism to detect what messages are newer than others. This can be achieved through a version identifier or by assigning a timestamp to each message when it is accepted by the system. |
Relaxing message order by only guaranteeing it on a per-key basis allows the system to parallelize message exchange and processing. As a result, the system can scale by adding partitions or brokers to the messaging layer and increasing the number of replicas to process messages.
Stateful computation
Each service must be able to declare what messages to store for further processing. This enables services to build their own state based on the processed resources from source systems, eliminating the requirement to request additional data from those sources. This guarantee is important for real-time data processing through event streams, since it helps achieve low end-to-end latency, high throughput, and parallelism. The ability of each service to build and reuse its own state makes the platform easily scalable, since no external data storage is required.
| Thanks to this guarantee, we can decouple the performance, scalability, and availability of the Digital Experience Mesh from the source systems. |
| If you are interested in learning more about Stateful Computations over Data Streams, explore Apache Flink, which solves similar problems in a more general way. |
Schema enforcing
The system must be able to validate the message against the schema before accepting it. This ensures that only valid data is processed by the system, reducing the risk of errors later on. If the message does not conform to the schema, the system should reject it and provide an appropriate error message.
Backpressure handling
The system should provide a backpressure mechanism, allowing each service to operate at its own pace. Messages that cannot be processed at a given time should be queued for future processing. Adding more service instances should help distribute the load and balance it across replicas to increase the processing throughput.
| In some cases, different backpressure handling mechanisms are allowed, such as dropping messages if the delivery guarantee is less important than the relevance of the data. For example, a price update service can prioritize recent prices over historical prices. |
Failures handling
The system should implement a Dead Letter Queue (DLQ) to handle messages that repeatedly fail to be processed. When a message cannot be successfully processed after a defined number of retries, it should be moved to the DLQ for further inspection or manual intervention. This ensures that failed messages do not block the processing of other messages and allows the system to continue operating despite errors without losing data.
| Other failure handling mechanisms are permitted, including dropping messages or marking the service unhealthy. |
Next-generation push model
The previous sections were focused on reasoning why a new architecture is needed to address problems that traditional approaches couldn’t solve. We also broke down the issues and mapped them to the characteristics and guarantees that the Digital Experience Mesh must provide. Starting from this section, we’ll explain how the Digital Experience Mesh works, what are its principles, and the consequences of choosing it.
Most traditional web systems have been designed around the request-reply model. While this model is still required due to the nature of the HTTP protocol, we find it ineffective in a way we use it now. Requesting the state of origin systems every time data is needed forces us to rely on caching mechanisms for scalability. These caches become difficult to manage and are often overused, leading to negative side effects on the application. Such issues might include outages caused by cache purges, when the origin servers can’t handle the load, or the risk of serving stale data, including cached items from other users' sessions. Moreover, over-reliance on the request-reply model, built around centralized applications, creates tightly coupled architectures that are hard to scale or modify in the future. Such an architecture introduces multiple bottlenecks and single points of failure, making the systems expensive to maintain.

To address the challenges identified over years of working with traditional web systems, a new model must be introduced - one that is loosely coupled, responsive, and scalable. The model must provide a complete end-to-end solution for working with services and managing data orchestration and processing. The Digital Experience Mesh is an architecture that promotes the push model over the request-reply model, making it the standard communication approach within the system.
| The idea behind the push model is to process the maximum amount of information before the user requests data or calls a service. This also involves sending the data to services deployed close to the users. |
To implement the push model, the Digital Experience Mesh must be event-driven, distributed, and stateful.
DXM is event-driven
To start building event-driven systems, in contrast to the more popular request-driven (polling) systems, a shift in mindset is required. For example, a common use of event-driven design is how a webpage is rendered in the browser. Each link on a page has onClick handlers that instruct the browser what to do when a visitor clicks an anchor. If we think about it, there’s no requirement to periodically query the DOM to check the status of components, such as those clicked and those not clicked. We’re simply interested in reacting to user actions.
The same approach applies when designing interactions between systems or components in a broader web system. For tasks like rendering a page or optimizing an image from a DAM system, querying the source system and running application logic based on its current state is unnecessary. Instead, the focus should be on events—such as a new page version being published or a new image rendition being activated. Rather than repeatedly checking the source system, we can respond to these events with a series of actions. These actions can trigger additional workflows until the final output, like a rendered page or optimized image, is stored at its destination. The result of each action can trigger parallel actions or workflows, for example indexing the page in a search engine, updating listings, or generating a sitemap.
The consequence of understanding the importance of event-driven architecture is that the system can:
-
Respond faster, because actions are triggered immediately when a change occurs.
-
Be more scalable, since any component can respond to an event without being a bottleneck.
-
Be more responsive, because it can react quickly to individual (atomic) changes rather than processing the entire system state.
-
Be decoupled from the event source, including its location, performance, and availability.
-
Be geographically distributed, because the system knows exactly when to trigger distribution.
| Most web systems, such as e-commerce platforms, CMS, and PIM systems, include an eventing layer that can be used to notify external systems about changes within the system. This can be leveraged to integrate with the DXM. |
DXM is distributed
There are two key aspects of a distributed web system:
-
How to distribute the load to allow multiple instances of services to process requests.
-
How to distribute data to make it available for services in different geographic locations.
| Layer | Type of distribution |
|---|---|
Sources |
Source locations cannot be controlled by the Digital Experience Mesh. All locations are supported. |
Processing |
Multiple availability zones within one region to ensure low end-to-end publication latency. Multiple instances of the same service type participate in processing data pipelines. Load is evenly distributed between instances. |
Delivery |
Multiple geographic locations, including edge locations, to achieve the lowest possible latency between delivery and client devices. Multiple instances of the same service type participate in processing incoming internet traffic. Each service instance must process every incoming change. |
The goal is to push data closer to the user geographically, minimizing the distance and time required for the client to pull data. This is achieved by composing the system of small, independent services rather than a single monolithic application. Each service only receives the data relevant to its needs. The service declares the types of changes it will track and is responsible for maintaining its own state. This ensures that the amount of data to replicate is relatively small and optimized by the receiver.
DXM is stateful
As mentioned earlier, to enable data distribution and event-driven use cases, the Digital Experience Mesh must be able to maintain state.
Each service is responsible for maintaining its own state. This means that the service must subscribe to events of a given type, convert the data, and store it locally for future use. New service instances must be able to recover their state based on historical events, which requires external data storage used only during service initialization.
| To learn more about creating internal state from events, refer to the Event Sourcing pattern. |
The fact that each service maintains its own state makes the Digital Experience Mesh horizontally scalable with fine granularity. It is possible to scale the system on a per-service basis.
| There are processing techniques that do not involve state management, such as serverless computing. These functions are limited to specific use cases where little to no data is required. |
Consequences
The combination of the fundamental design decisions mentioned in this section leads to several consequences. To provide more context, let’s explore some examples.
-
Reducing the number of network calls to backend systems:
 Figure 8. Number of network calls to backend systems
Figure 8. Number of network calls to backend systemsThe number of network calls to the backend system is reduced from 5 to 1, significantly improving efficiency. Since the backend systems might be deployed in different locations, multiple calls could introduce additional network delays. By making a single request to the nearest delivery service, these delays are minimized, resulting in better overall performance.
-
Reducing the number of services involved in computation:
 Figure 9. Number of involved services
Figure 9. Number of involved servicesPerformance is affected not only by network calls and internet infrastructure delays but also by the time it takes each requested service to handle a request. Each service must open a session, query a database or cache, and return the result, all of which add to the processing time. By reducing the number of services involved from 5 to 1, we can significantly streamline this process and improve overall performance.
-
Reducing the number of services that must be replicated:
If a service is not involved in the computation, it doesn’t have to be geographically replicated to optimize performance, which reduces complexity and infrastructure overhead.
-
Reducing the number of points of failure:
If a service is not involved in the computation, by not calling it during that computation, an additional point of failure is eliminated. As a result, backend system performance and availability no longer become runtime dependencies for site visitors.
-
Reducing the number of services that must be scaled:
When the system must handle increased load, only the services directly involved in the computation must be scaled. This enhances scalability and reduces overall costs by avoiding unnecessary resource allocation for unused services.
-
Reducing the security attack surface:
If a service is not involved in the computation and is not a runtime dependency, it does not have to be publicly exposed. This significantly improves security.
-
Reducing the role of caching layer:
 Figure 10. Cache layer introduced for performance and availability
Figure 10. Cache layer introduced for performance and availabilityThere is a high probability that systems will require caching mechanisms to handle the load coming from clients. This can lead to issues with caches, such as complex invalidation mechanisms, stale data, or cold cache problems. Overusing caches increases the complexity and maintenance costs of the system. With the Digital Experience Mesh, the caching layer is not needed between backend systems and the delivery service.
-
Ability to replay state of the backend systems:
The system already holds a state that reflects the states of the backend systems. This means that, in most cases, switching one component, like a search engine implementation, to another would not require re-publishing historical products, pages, prices, or reviews.
The consequences mentioned above are just examples and not an exhaustive list. However, they help illustrate how shifting from a traditional request-reply model to a modern push-based architecture fundamentally changes the system’s characteristics.
Mesh concept
Having defined principles such as event-driven, message-oriented, microservices-based, stateful, and distributed systems, along with the required system characteristics, forms the foundation for creating a comprehensive architecture. The Digital Experience Mesh is a concept designed to address key challenges in modern web systems, including performance, scalability, and availability.
As mentioned earlier, developing a successful architecture involves more than just identifying principles. It requires a clear understanding of its components, their roles, and the way they interact with each other. This section focuses on defining those components, organizing them into logical layers, and establishing guidelines to ensure predictable and repeatable results in system design and implementation.

The Digital Experience Mesh architecture defines three component layers:
-
Source Systems: External systems that feed the Mesh with data updates by sending events through the Ingestion API.
-
Processing Layer: Services and channels that are building blocks for creating pipelines involved in data processing.
-
Delivery Layer: high-performance services deployed in locations close to users, used to deliver content or functionalities.
Aside from sources and services, we can identify other components:
-
Ingestion API: Responsible for accepting events from Source Systems.
-
Channels: Used to deliver messages between services.
-
Stores: Local data views created on instances of a service, updated and synchronized by using channels.
-
Volumes: Storage to persistent data after processing.
| In the context of the architecture, the Mesh is composed of all the components, beginning with the Source Systems definitions, needed to handle authorization and authentication. However, the Source Systems themselves are not part of the Mesh. |
The framework must enforce the composition and execution of the Mesh. It should define message contracts and provide methods for registering and validating schemas. Additionally, the framework is responsible for distributing the load across processing services and ensuring that services are in a valid state before processing starts. For more information about framework requirements, see Key guarantees.
| The term 'Mesh definition' refers to a set of rules and configurations required to deploy a functional mesh in an execution environment. This definition might take the form of a YAML file, along with any additional configurations when needed. |
Source Systems
Source Systems represent the origin of data ingested into the Mesh. The Mesh definition must explicitly specify sources that are permitted to send messages to specific channels. Based on this definition, the Ingestion API will manage the authorization and authentication processes. In addition, the Ingestion API is responsible for schema validation, ensuring that only valid messages are accepted.

The example above shows the CMS that can publish events to the pages, assets, and templates channels, but it cannot send updates to the products or prices channels. The CMS must also ensure that the message payload is valid, because invalid messages will be rejected by the Ingestion API.
Other common source systems include PIM systems, e-commerce systems, DAM, headless CMS, legacy APIs, or bash scripts executed during CI/CD pipeline execution. The last example is particularly interesting because it allows changes to be deployed directly from the Git repository. Another relevant source in the context of this architecture is user actions. For example, we can track user activity to generate real-time recommendations that use machine learning algorithms.
| Not all systems can push updates. For some legacy systems, it might be necessary to create a scraper that periodically checks for changes (deltas) in the REST API responses and sends them to the Mesh, or to use a script that retrieves this information directly from the database. |
Processing Services
Processing Services are services that read from and write to channels. These services contain functions that can be composed together to build a data pipeline. Multiple instances of a single service can operate at the same time, with messages being equally distributed between all instances. If a service is stateful, meaning it maintains a state built from historical events, the framework must enforce synchronization between service instances. An instance must ensure that all historical data has been read before it can start processing incoming messages. New instances of a service must automatically initialize their state before being enabled in the Mesh.
If a service cannot process a message within a given time, the framework can automatically reassign the message to a different instance, ensuring the message is eventually processed. Services must also reject outdated messages.
An example of a processing service might be a Sitemap Generator that listens for page publication events, generates a sitemap, and sends it to a web server through the resources channel. Another example is a Rendering Engine that listens for data and template publications and generates a page publication event in response. Note that the Rendering Engine might trigger the Sitemap Generator, resulting in the following pipeline:

In this example, the Rendering Engine uses multiple instances of the service, and each instance should maintain its own state built from historical Data and Template publications. This is necessary because rendering a page requires both data and templates, and each service instance can process only one event at a time. The Sitemap Generator also uses a local state, but it doesn’t require synchronization since there is only one instance of the service. Therefore, only the Rendering Engine requires synchronization.
Delivery Services
Delivery Services are services that read from the final channel in the mesh, and cannot write to any channels. These services contain functions that send the final events processed by the previous layer to a sink. The sink is the terminal step of a pipeline and represents the final destination of the data, such as a search index, volume, or database. Multiple instances of a single service can operate simultaneously, with all messages delivered to each instance. This differs from the semantics of processing services, because in this case, the goal is to increase the throughput of the delivery layer. For example, when adding a new instance of a web server, it must consume all the pages, even if other web server instances have already processed them. New service instances must automatically initialize their state before being activated in the Mesh.
Each service instance is a complete copy of both data and functionality. This allows the system to scale horizontally in a linear fashion. Moreover, it increases redundancy of services and data, improving both availability and resilience. As a result, there is no single point of failure in the system.
Example delivery services include:
-
Web server
-
Search engine
-
GraphQL database
-
A microservice
| It’s possible to create a custom microservice with any database, framework, or logic, which enables a wide range of use cases for the Digital Experience Mesh. |
Mesh composition
A Mesh is a complete set of sources definitions and pipelines deployed in an environment to orchestrate multiple sources of data and deliver the results to various channels. The Mesh contains business logic and executes a series of actions.
To simplify the design, building, testing, and maintenance of meshes, it is important to recognize that pipelines are often independent. Breaking the Mesh into smaller pipelines and composing them together later is an effective technique for managing complex setups.

In the example above, the image optimization pipeline is separate from the page rendering pipeline. As a result, it can be developed, tested, and deployed at a different pace, or even by a different team.
Technological choices
The Digital Experience Mesh does not enforce the use of any specific technologies to implement the architecture. However, there are modern technologies that align well with its concepts or provide the necessary capabilities. This section highlights compatible technologies to help clarify the challenges that must be addressed from a technological perspective.
Microservices
Microservices are a key architectural pattern that aligns well with the principles of the Digital Experience Mesh. By breaking the system into smaller, independent services, microservices enable flexibility, scalability, and maintainability, which are critical for modern web platforms. While it’s still theoretically possible to use alternative technologies like Serverless Functions or Modular Monoliths, microservices seem to offer the right balance between control and modularity.
Event streaming
Event streaming is another crucial technology that supports the event-driven nature of the Digital Experience Mesh. Event streaming platforms, like Apache Pulsar or Kafka, are designed to process real-time data streams with high throughput and low latency. Event streaming platforms are designed to be fault-tolerant, scalable, and provide strong message delivery guarantees such as at-least-once or exactly-once delivery, ensuring that important data is never lost.
If microservices together function like a brain, then event streaming plays the role of the spinal cord carrying the messages. Both enabling the system to be responsive, scalable, and efficient in processing real-time data pipelines.
While other messaging technologies can be used to build channel abstractions, only event streaming can achieve the scale and performance required for modern web systems.
Log-based storage
A log-based architecture provides an abstraction for data storage. There are multiple database types, including relational, document, key-value, and object databases. However, for working with event streams, log-based structures and the key-value stores built on top of them are the most efficient.
-
Single source of truth: Log structures append new events to the end of the log and ensure immutability, allowing all services or instances to access a consistent and unified state.
-
Recovery and replay: Logs enable recovery to a specific point in time or the selective replay of events. For example, logs can be used to re-index all published pages without querying the current state.
-
High efficiency for stream processing: Logs are simple and highly efficient. Data is read from a stream without blocking or waiting for results. Utilizing log structures enables real-time data processing.
-
Simplified Schema Evolution: There is no requirement to evaluate complex relationships between data entities.
-
Consistency and Fault Tolerance: Logs are easy to replicate and typically fault-tolerant.
In some scenarios, especially when data must be accessed by query or key, it is necessary to build additional abstractions on top of logs. However, logs remain the default primitive to consider when implementing the Digital Experience Mesh architecture.
Container orchestration
A container orchestration engine is preferred for implementing the Digital Experience Mesh architecture because it automates the deployment, scaling, and management of containerized services. DXM relies on microservices and distributed components that must run reliably across multiple environments. Container orchestration engines, such as a Kubernetes resolves most of the challenges of these setups.
| We encourage you to explore microservices, event streaming, and container orchestration further, because these topics are beyond the scope of this document. |
What problems does it solve
To truly evaluate the value of an architecture, it’s essential to identify the real problems it solves rather than just offering minor improvements. After all, proposing a higher-performing system is pointless if the current ones aren’t struggling with performance in the first place. In this section, we will map the core features of the Digital Experience Mesh to alternative solutions that are widely used to address similar problems. If no direct alternatives are available, the comparison will focus on the closest possible options.
| This section defines core architecture features. |
The examples used in this section represent recurring problems we encountered both before and during the process of defining the Digital Experience Mesh architecture. The summary below shows how the architecture’s features are mapped to alternative technologies, with more detailed descriptions provided in the following sections.

Multi location availability
A Content Delivery Network (CDN) is widely used because it improves website performance by distributing content across various geographic locations, reducing latency for users. It enhances scalability, allowing websites to handle traffic spikes without performance degradation. Additionally, a CDN improves reliability and security by providing redundant server locations and protection against online threats like DDoS attacks.
However, there are certain limitations of a CDN:
-
Cache dependency: A CDN is a cache for the origin server, which reduces but does not eliminate not eliminate the origin’s role entirely.
-
Challenging cache management: Managing the cache lifecycle can be complex, especially when it comes to setting the correct time-to-live (TTL) and effectively applying invalidation rules.
-
Limited to static content: A CDN is designed specifically for serving static content, making it ideal for assets like images, JavaScript, CSS files, or fonts. However, it cannot enhance the performance of dynamic content or services.
-
Cold-cache challenges: Addressing cold-cache scenarios can be difficult and might lead to performance issues.
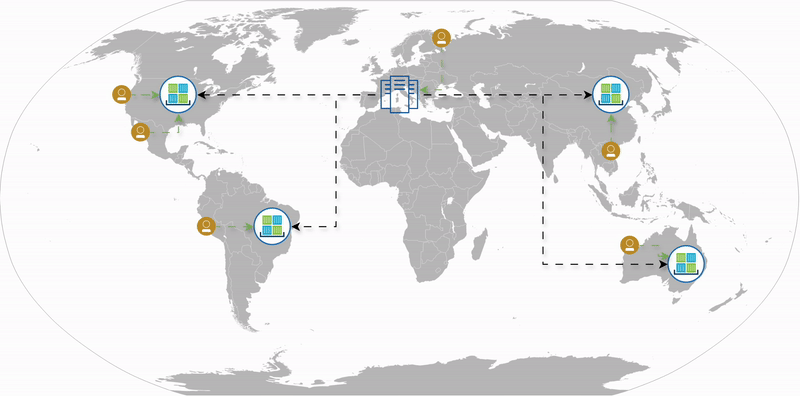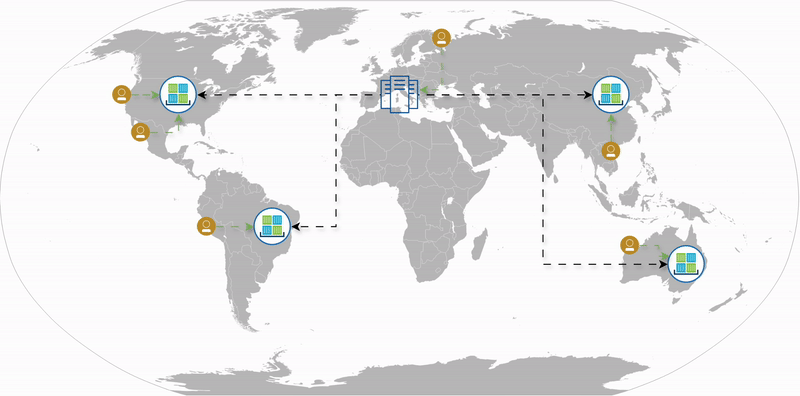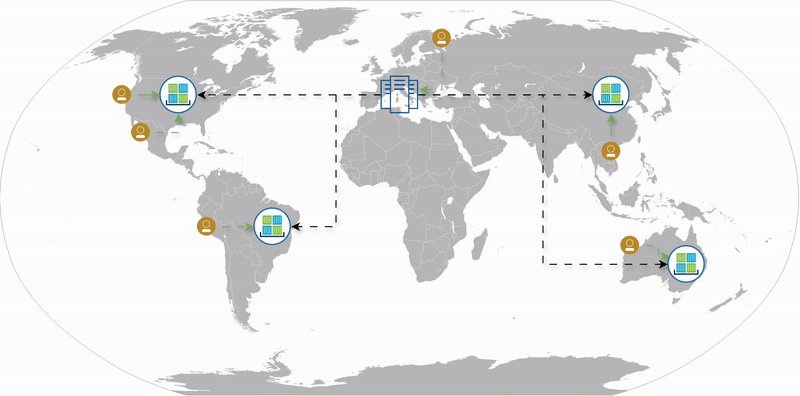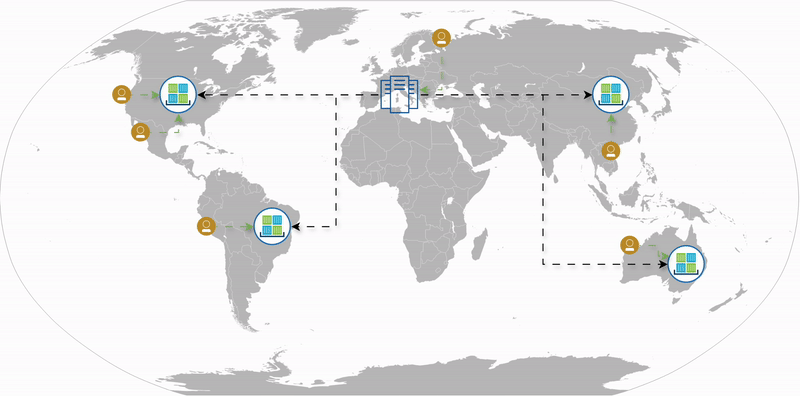
The Digital Experience Mesh (DXM) can complement a CDN by distributing both services and data. It enables the deployment of services closer to users, allowing data to be served in the static and dynamic form. Unlike a request-reply cache, DXM utilizes a push-based architecture, offering complete control over the availability of data at each location. Resources are pushed to edge locations ahead of time, making them available before the user requests them. This results in performance gains from the first request, meaning there are no cold-cache or cache invalidation issues. Consequently, the site’s availability is no longer dependent on the origin server’s availability.
| Problem |
Multi location availability |
| Similar to |
CDN |
| Like |
Like a CDN, improves performance, availability, and reliability. |
| Unlike |
Unlike a CDN, it uses a push-based approach, making it suitable for static resources, dynamic content, and services. |
Data orchestration
In traditional web systems, integrations — including data orchestration — were often handled through custom implementations within the system’s codebase. Most CMS and e-commerce platforms were able to communicate with external services and process data. However, with the increasing complexity of integrations, especially in enterprise organizations, more sophisticated solutions like Enterprise Service Buses (ESB) were employed. These solutions reduced the number of point-to-point integrations and offloaded systems like CMS from being the integration hubs.
The situation became more critical with the shift to headless and cloud technologies, because many headless systems lack built-in integration capabilities. The challenge of integrating multiple headless and legacy systems, including orchestrating data, became so widespread that a new software category emerged: Digital Experience Orchestration. This category focuses on managing the orchestration of data and services in relation to web systems. The Digital Experience Mesh, which is a middleware solution, is perfectly positioned to take on this role.
ESB products are not inherently designed to work with modern web systems. As a result, they are often monolithic applications, centrally deployed in an organization’s data center, which creates a single point of failure and limits both performance and scalability. ESB systems also lack the real-time performance found in event-streaming platforms, which can introduce additional processing and request latencies. Additionally, ESB systems come with complexity and overhead, whereas lightweight, decentralized approaches that favor agility and faster integration cycles are better suited for web systems.
The Digital Experience Mesh, a distributed, microservice-based system driven by events, is an excellent option for building integrations. Its powerful integration capabilities, along with near real-time processing and high throughput, can deliver significantly better results for the needs of modern web systems.
| Problem |
Data orchestration |
| Similar to |
ESB |
| Like |
Like an ESB, the Digital Experience Mesh can be used to orchestrate data and integrate services. |
| Unlike |
Unlike an ESB, it is a lightweight, distributed, low-latency, and high-throughput architecture specifically designed for web systems. |
Ahead-of-time processing
It is a common technique to pre-generate resources before making them available for consumption. A common example is Static Site Generators (SSG), which are used to build a static version of a site before deploying it online. Incremental Static Regeneration (ISR), a technique developed by the Next.js team, is more sophisticated. Instead of generating the entire site at once, it allows for per-page generation based on specific events. ISR retains the benefits of SSG but scales efficiently to millions of pages.
Moreover, similar techniques are used when working with data. Data pipelines are often built to perform data transformation and optimization while moving data from one place to another. Preprocessing data allows operations to be performed on an optimized, often smaller dataset, resulting in faster querying and processing.
SSG usage is often limited to relatively small sites due to the time required to generate the entire site. While ISR partially solves this problem, it remains a basic technique that cannot manage custom relationships or respond to events beyond data changes. Additionally, there is a lack of standardized methods for building data pipelines for web systems that can work with both SSG and ISR, without requiring time-consuming and resource-intensive development.
The Digital Experience Mesh has the capability to pre-generate resources such as pages, fragments, or data. Pipelines for generating these resources can be triggered by various events from multiple systems, such as template updates, data changes, or content updates. Data pipelines can be used to efficiently optimize event-driven data for feeding services, enabling the system to deliver more than just statically generated resources. By utilizing optimized data, the system maintains high performance and scalability.
| Problem |
Ahead-of-time processing |
| Similar to |
SSG, ISR or custom data pipelines |
| Like |
Like to an SSG/ISR, the Digital Experience Mesh can be used to generate static sites. |
| Unlike |
Unlike SSG/ISR, it can be triggered by any event to selectively regenerate specific resources and includes built-in data pipelines and services. |
Real-time data processing
Real-time data processing is becoming the standard for handling data. Unlike batch processing, real-time updates offer systems higher-quality and more consistent data. However, web systems have traditionally been built around monolithic applications, relying on a single database to store all system information. This created multiple problems, especially because databases used by systems like PIM, CMS, or e-commerce platforms were never optimized for handling large datasets. What’s more these systems were not designed to move and process data efficiently. It’s common for organizations to tolerate outdated information available on their websites, such as product details or availability, which can only be updated once a day. Batch price updates can lead to significant financial losses if the company is unable to adjust its pricing strategies in real time.
As a result, more companies are adopting streaming platforms like Apache Kafka and Apache Pulsar. Real-time data processing frameworks and engines, such as Apache Flink, are also becoming increasingly popular.
Designing and developing custom data platforms based on the mentioned technologies is expensive. There is a shortage of specialists in the market with the skills to effectively design, implement, and manage these systems. The time and resources required to implement and maintain such solutions often exceed the capabilities of medium-sized organizations.
The Digital Experience Mesh leverages event streaming to enable stateful computations over data streams and is designed specifically for web-related use cases. This approach achieves similar outcomes without the complexity of managing low-level event streaming platforms. The architecture abstracts data sources, processing, and delivery, while providing the necessary guarantees to meet most web-related requirements.
| Problem |
Real-time data processing |
| Similar to |
Apache Kafka/Pulsar/Flink |
| Like |
Like event streaming and processing platforms, it can perform stateful computations over data streams. |
| Unlike |
Unlike the alternatives, it is designed specifically for web-related use cases and provides an abstraction that solves most challenges with a fraction of the resources. |
Unified data layer
Monolithic web systems often tend to be neither high-performing nor scalable. As a result, teams frequently try to offload unnecessary data from their repositories. Search indexes like Elasticsearch have become a standard way to create an additional data layer. This solution becomes even more popular when multiple systems contribute to the repository. Search indexes are fast, easy to use, and can be directly queried by frontend technologies to build responsive interfaces for web systems.
However, when a web system grows, search indexes - never designed to serve the role of a unified data layer for web systems - begin to hit their limits. It might be easy to start with, but working with a storage system that holds unstructured documents, lacks relationships, and has no clear data ownership can become challenging. Search indexes often slow down when the incoming data is not optimized, leading to the need for replacing multiple point-to-point integrations with standardized pipelines. Such a solution becomes expensive to build and operate, while still failing to address issues like geo-replication. Additionally, search index APIs are not designed to handle different types of resources, such as XML, JSON, or HTML files, without additional processing.
The Digital Experience Mesh can address the issues associated with search indexes. The architecture is designed to connect multiple Source Systems and process data before sending it to the Delivery Layer, which could be a search engine, GraphQL, or a web server. The system includes built-in authorization and authentication for the Source Systems, ensuring clear ownership and control over the data. A schema, enforced and validated during ingestion, guarantees the accepted data is consistent and of high quality. It also includes built-in geo-replication capabilities and can serve any type of resources, not just searchable documents.
The Digital Experience Mesh addresses similar challenges to a search index. It can fulfill the role of an external data repository but offers a more comprehensive solution for building and managing the Unified Data Layer.
| Problem |
Unified data layer |
| Similar to |
ElasticSearch |
| Like |
Like Elasticsearch, the Digital Experience Mesh can be used to provide a unified data layer. |
| Unlike |
Unlike Elasticsearch, it orchestrates data by using data pipelines, supports geo-replication, enforces schemas, and ensures clear data ownership. |
Core data pipelines and services
The Digital Experience Mesh is an architectural paradigm created to address various web-related use cases. Although it’s not mandatory for the system to provide specific pipelines or services, describing common use cases can help in understanding. Traditionally, the functionalities outlined in this section were handled by monolithic applications like a CMS. By offloading these functionalities to a new, event-driven, and distributed architecture, the system can improve its operations and enable use cases that were previously impossible.
Rendering pipeline
The content rendering pipeline, deployed to be a part of the Digital Experience Mesh, can offload source systems from rendering and is ideal for integrating headless backend systems. Rendering occurs once per data or template change, meaning it doesn’t happen in the browser for every user, unlike with the use of modern frontend frameworks.
Data and templates used in content rendering pipelines can be sourced from multiple systems. Depending on the use case, templates can be produced by a CMS or stored in a source code repository. The end result of the rendering process is a static HTML file placed directly on a web server. This approach produces frontend-optimized resources, which are much faster to render on the browser side. Since all necessary resources can be composed within the Digital Experience Mesh, no additional data will be fetched over the network. This results in highly efficient pages with improved Lighthouse scores, optimizing both performance and user experience.
Various technologies can be used to implement a rendering engine, including simple templating libraries or modern frontend frameworks.

Composition pipeline
Composition is similar to a rendering pipeline but is focused on decorating fragments with predefined templates. An example source of fragments could be HTML content files generated from transforming Markdown or AsciiDoc files, such as a documentation page. This page can then be decorated with a template to include necessary styles, global navigation, and other elements. While rendering requires providing code or a template, composition is designed to handle the relationship between content layout and content fragments.

Late includes handling
In some cases, it’s not optimal to use composition for handling layout-to-fragment relationships. The composition pipeline can be very resource-intensive and might produce a large number of outputs if a commonly used fragment is changed. For example, if there is a single navigation menu shared across a million pages, an update to the navigation would trigger the re-composition of all those pages. Additionally, once the pages are republished by the composition service, it can trigger other pipelines, such as search index updates or sitemap updates.
To overcome this issue, late includes resolution is needed. With this technique, we can postpone the resolution of content fragments and execute it on a web server, a CDN, or even in the browser. Common techniques that help achieve this include Server-Side Includes (SSI), Edge-Side Includes (ESI), or JavaScript calls.
It is preferred that all delivery services, such as Search, provide similar functionality. This way, indexing content within a header would not require re-indexing each page separately.

Enterprise Integration Patterns pipelines
Web systems, especially headless ones, frequently exchange data. To prevent repetitive implementation, the Digital Experience Mesh should include simple, reusable services to help build data pipelines. Enterprise Integration Patterns (EIP) cover most common use cases, such as aggregation, filtering, or enrichment of messages. Since the Digital Experience Mesh is a message-driven, asynchronous system, implementing these patterns is a natural choice for handling the data.

Sitemaps and listings pipelines
Traditionally, generating sitemaps and listings has been managed by monolithic systems like CMS platforms. This approach was straightforward when a single system controlled all the data. However, it often required data from other systems, such as product information from a PIM, to be imported into the CMS repository. This approach leads to performance and scalability bottlenecks, creates a single point of failure, and prioritizes one system over others—often without sufficient justification.
An alternative approach, driven by the need for real-time data processing, is to create data pipelines that offload this responsibility from the CMS. By generating listings and sitemaps outside a single system, hybrid deployments with multiple content sources become more feasible and scalable.

Search index pipeline
Traditionally, search functionality was built into one of the systems, often a CMS or an e-commerce platform. However, embedded search features typically lacked the performance, resilience, scalability, and advanced capabilities of external search indexes. As a result, many setups now incorporate a dedicated search index for better performance. The challenges do not lie with the search indexes themselves but with how the data is governed. With multiple source systems, it becomes difficult to create a unified search that doesn’t rely on point-to-point integrations, enforces a common data structure, and provides consistent search results.
The Digital Experience Mesh pipelines can be used to enqueue data for ingestion, enforce schema and data structure, and ensure data quality and ownership. It can be also used to provide additional features, like geo-replication of a search service and data.

Image optimization pipeline
Traditionally, image renditions are created either after uploading the image to a DAM system or by converting them at the CDN level. The second option is a paid service, which can be expensive due to the amount of computing power required for conversion. Additionally, since a CDN is distributed, converting an image in one region does not guarantee that the converted image will be available in other regions. The biggest issue with late conversion is that for the first requests, the conversion takes a significant amount of time, greatly degrading the user experience.
The Digital Experience Mesh pipelines can be used to produce optimized images regardless of their origin. Optimization can be performed ahead of demand and distributed to servers in various geographic locations before users request them. Additionally, it’s possible to track updated images and rewrite the references in HTML files, so no changes are required in the source systems responsible for rendering the HTML.

Recommendations pipeline
The Digital Experience Mesh can be used to create a high-performing, web-scale recommendation pipelines. Events gathered while tracking the user’s journey can be sent back to the Digital Experience Mesh to generate content recommendations. These recommendations can be made immediately available to the end user because the processing occurs right after a user action, such as opening a product page. A pre-generated recommendation is ready to be included on another page before it’s requested. This eliminates the time required for the recommendation system to generate a response and ensures an optimal user experience.

Alternative ingestion methods
Not all source systems, especially SaaS-based or legacy ones, can send events by using dedicated APIs. In such cases, there are several techniques to feed event-driven systems with data:
-
Retrieving data from a repository, such as S3.
-
Scraping REST APIs to capture data and sending the delta (changes) to the event-driven system.
-
Connecting to an existing messaging/event system available in the solution.
-
Exposing a URL that can be used by third-party webhooks.
In some cases, fetching data from external systems or endpoints might be easier to implement and maintain. The Digital Experience Mesh should include a microservices framework that facilitates this.
