
by Michał Cukierman
10 min read
by Michał Cukierman
10 min read

Composable DXP is a trending topic in the digital landscape nowadays. Let's have a look at what are the options available on the market and what are the use cases for them.
Let's start with a question: Can composability improve your page performance?
It depends on the way you approach the problem. After analyzing the offers of MACH Alliance members, it looks like there are two possibilities. One is to leverage frontend technologies and build the integrations based on the client's device, most commonly a browser. Such front-end technologies are backed by client-specific microservices. The second is the new category of middleware - Digital Experience Orchestration (DXO). Such middleware is the orchestration service that governs the calls to internal systems.
So the options we have are:
Frontend Integrations
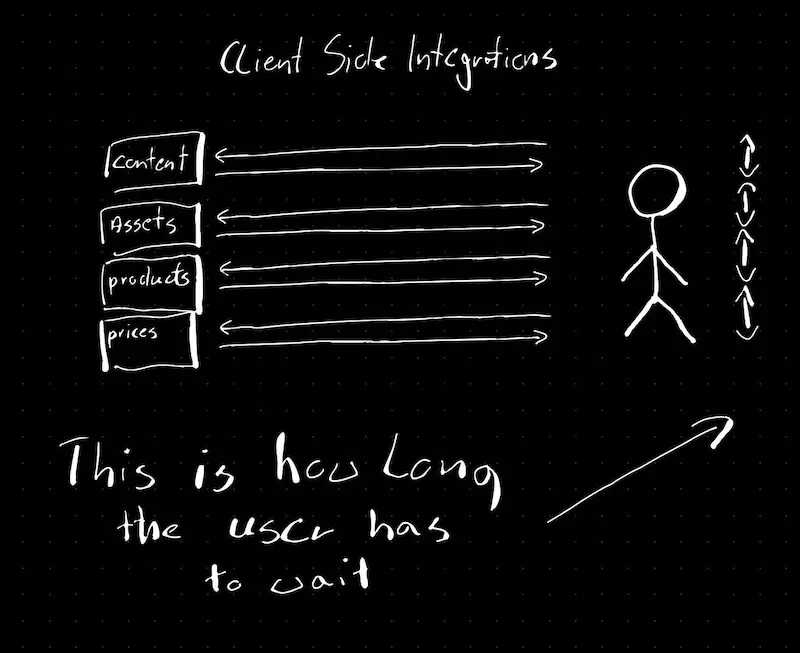
Integrations on frontend backed by microservices (classic MACH approach)
Server side integrations
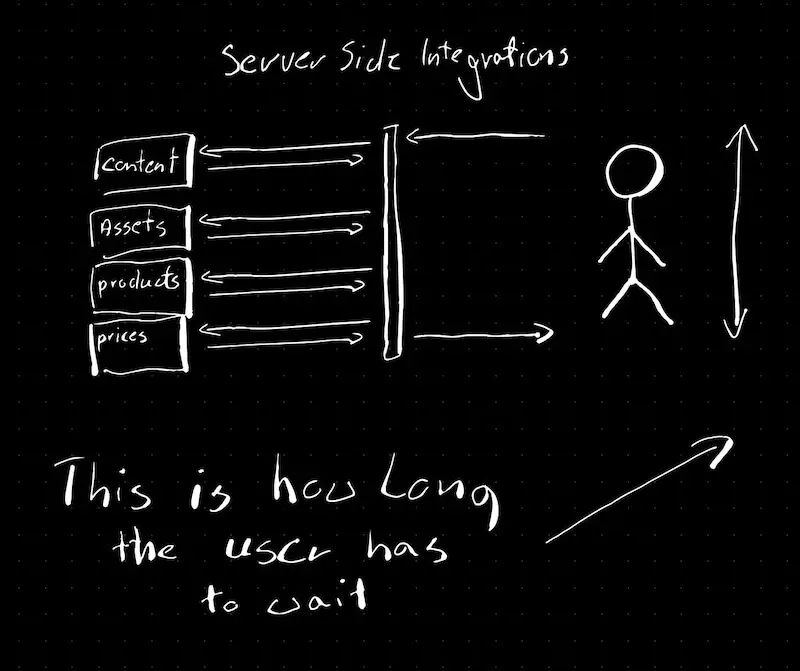
Integrations using middleware (DXO) or traditional setup (CMS)
The left one seriously affects the customer experience and SEO/lighthouse results.
The one on the right can be a bottleneck and can slow down the page load time, as we always need to wait for the backend services to respond (and if one of them is not performant, the entire site will be slow). In that way, takes the responsibility of integrating systems that in a traditional stack lay with the CMS. It solves some of the problems, and makes the platform more flexible, but does not address the performance issues (at least by looking at the architecture).
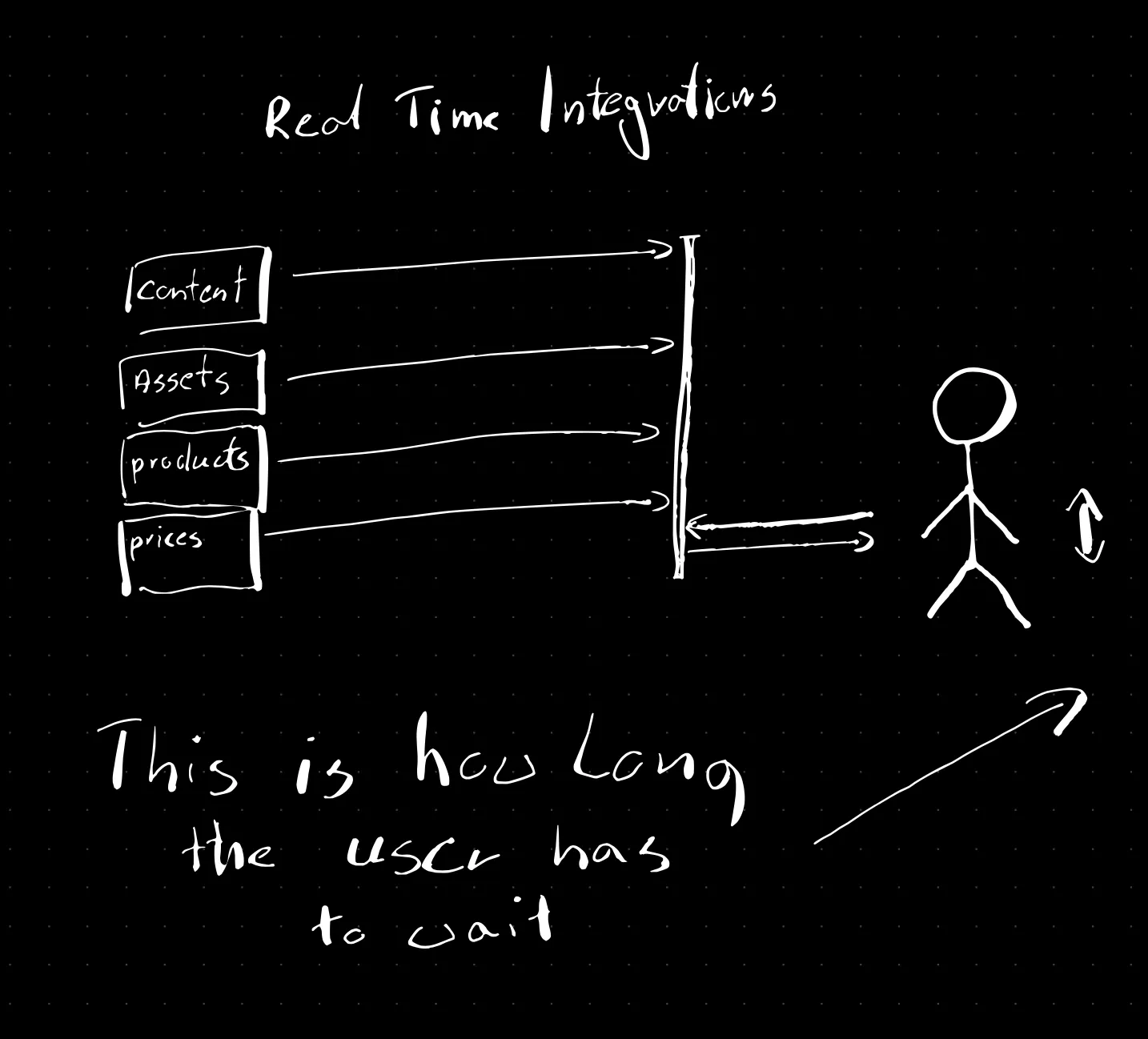
Real-time integration
I would like to present a third option we work on - real-time composability. We do it as a part of the StreamX project.
The key difference is that the platform does not request backend (often legacy) systems, but reacts to changes that happen in those systems by processing incoming events. This way we can always expect low milliseconds latencies (<10) when accessing any page, with keeping the data up to date. In other words, it means that you request a static page, that was already updated. It works similarly for the sitemap, search index, assets, or services. What’s more, if the back-end system is down, it stops sending the updates, but the site is presenting the most recent information that the back-end system sent while it was still up.
The first point I'd like to emphasize is:
The number of integrations
Source systems performance
do not affect the performance of the site.
To understand this approach we need to define what can be an event. We’ve been building web applications for decades, using request-replay methods (this is how HTTP works, right?), so firstly we need to unlearn what we know. In event-driven architectures, the systems are interested in being notified about the changes. Traditional stacks are more interested in the current state of the application. But the picture of the current state can be read from the events that happened in that system. One does not need to ask the system about its state when we register each event because if there is no event between the last notification of a change and now, there is no change in the state.
In the digital world, the examples of events may be:
E-commerce price change
PIM product update
Page publication
Asset update
User action that triggers ML to calculate the recommendation
Any system like CMS, CDP, PIM, or e-commerce can be a source. As long as it can notify the platform about the change.
StreamX reacts to changes that are used to trigger corresponding pipelines. The platform is not interested in the state of the system that was the source of the event. It does not request any additional data from it. It constantly updates sites to create experiences based on the continuous flow of updates. Notice that all the events are processed “ahead of time” before the user requests the page. What can be faster than a page or search index prepared before it’s needed?
I know it sounds good, but to be fair I should also mention the downsides of this approach.
It is definitely not a low-code and is not ready yet for small deployments. Make sure that it addresses the cases where the traditional approach fails. Especially when there are many integrations/sources. We can easily process tens of thousands of updates (publications, product updates) per second, with a $1000/month cluster. In theory, the upper limit does not exist, as the platform is fully horizontally scalable.
It comes with the cost of platform/solution complexity. I would not advise you to implement it in-house unless you are on Ebay or Netflix. StreamX project is the second iteration of the concept, reimplemented from the ground to address all the pain points we discovered. We aim to make the platform accessible without the need to spend years (or months, if you are ready to make mistakes and iterate) studying the implementation details. The main element in our long-term roadmap is to make it as simple to use as possible (does SaaS sound good?).
In our demo, we present the site with the data from:
PIM
Pricing service
CMS
Reviews service
We produce 1000 updates per second, each of the updates is available in:
Sitemap
Search index
Webserver
in constant time, less than 100ms.
While updating, we measure the page access time. If we do it from the laptop, it depends on your internet connection, but is lower than 50ms. The test run from the computer close to the cluster shows constant single-digit millisecond access time.
The second point I'd like to emphasize is the number of updates is not correlated with the site performance (with some edge cases, like using all the network bandwidth or all IO limits, but it’s rather a high limit).
It is the beauty of event streaming/reactive processing!
For the last 2 years, I haven’t found the direct competition. There are companies that specialize in event streaming and they offer i.e. real-time product updates, but it’s more like selling the expertise and the infrastructure, not something you can build a DXP around.
StreamX is dedicated to Digital Experiences. It works on abstractions like Publishing/Unpublishing. It takes care of ensuring message order, which is crucial for pages/search/services updates, but not so much in other cases where event streaming is used. We solved many issues i.e. how to scale webservers or functions automatically and most of all, you can extend the platform with simple APIs.
By default, the platform comes with:
Images/html optimisation
Pages publishing
HTML Templating
Search feed extraction
Data aggregation
Asset publishing
We are working on a real-time recommendation engine based on AI. The sites now use search and web servers, we are planning to add GraphQL db exposed for the front end.
For the integrations, apart from natively supporting our CMS, we added support for AEM and Magento, but in general, adding new sources is very easy. We have a backlog packed for the next 15 months, so expect to see more.
Transactional Databases are too slow and not scalable. DB operations also add additional latencies. Horizontally scalable databases do not guarantee consistency, which is not acceptable. We’ve introduced our own persistence layer, which is optimized for real-time processing. Such a layer can be used to replay past events, so we can always recover.
Customer-facing website is logically detached from the platform, it’s just subscribed for updates. The whole platform can go down, but the site will be accessible, you just stop to receive the updates from the source systems. This requires a change of thinking, as we replaced the request-reply model with the push model entirely (of course, you can still use request-replay for transactional use cases, that cannot be covered by real-time processing).
There is a correlation between the updates and customer requests. The limitation is the server network cable and SSD disk IOPs limits. We can scale the number of services (like web servers), introduce raid-based SSD, or even add an in-memory distributed data grid, but the limitation is rather theoretical.
What’s the most important:
There is no cache at all, as you don’t need one. We use NGINX servers which are always up-to-date, and a single instance can handle half a million requests per second (and still you can have any number of instances).
Caching is an option, but we haven’t found the use case for enabling using it.
StreamX demo is available on demand. The codebase is not publicly available. We will be working on the SaaS version, as it’s too complex to set up without deep technical knowledge. We can do it for production setups, but at least training will be required.
You can try our CMS demo using https://github.com/websight-io/starter , but it’s a different product, which is free to use with sources available.